eRegs API - a guided tour
This part of the documentation provides an explanation of the eRegs API and the design, storage, and view logic of the project.
Differences from old eRegs
The eRegs API is drastically revised from the previous version. Before the advent of eRegs 2.0, the eRegs deployment process involved breaking a regulation up into its constituent parts, storing those parts in the database as "layers", and then reassembling those layers into the final display version of the regulation. The diagram below illustrates the old eRegs content generation process:
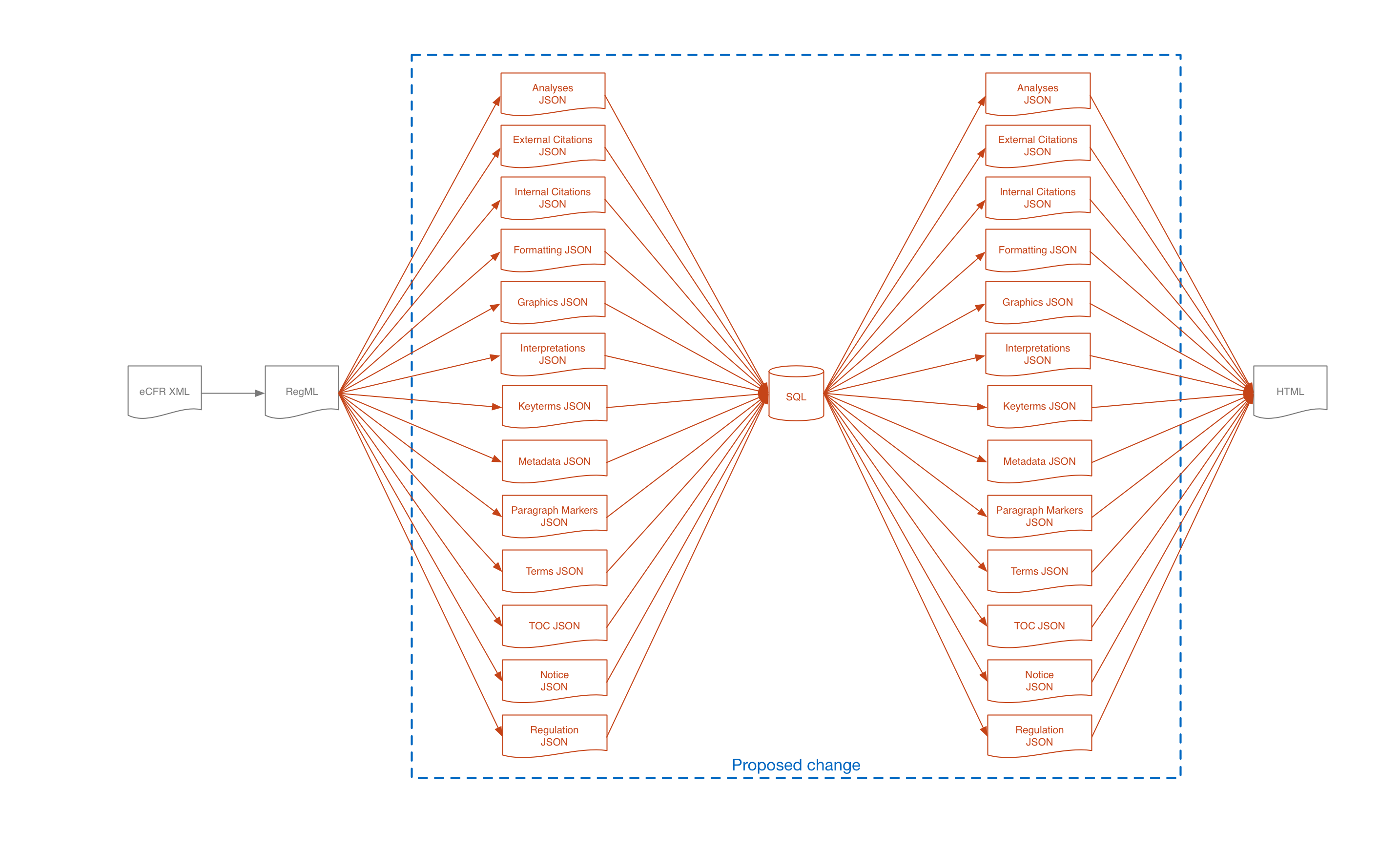
Not only was this process complicated and error-prone (in particular, the assembly of layers into the display HTML could fail in unexpected ways if some crucial piece of content was missing from the JSON layers), but it also took an extremely long time, especially for giant regulations like Z. Furthermore, because of the original design of eRegs, the storage logic actually lived in a different project called regcore which provided an API to regsite, which was the actual project that fetched the data and displayed it.
In the new version of eRegs, all of this complexity has been eliminated. The new eRegs stores the regulation tree directly in a single table and designates a node's position in the regulation tree hierarchy through the use of nested sets. The regcore project is eliminated entirely and display HTML is generated directly via server-side templating. The result is the following conceptual diagram, encompassed by a single project:
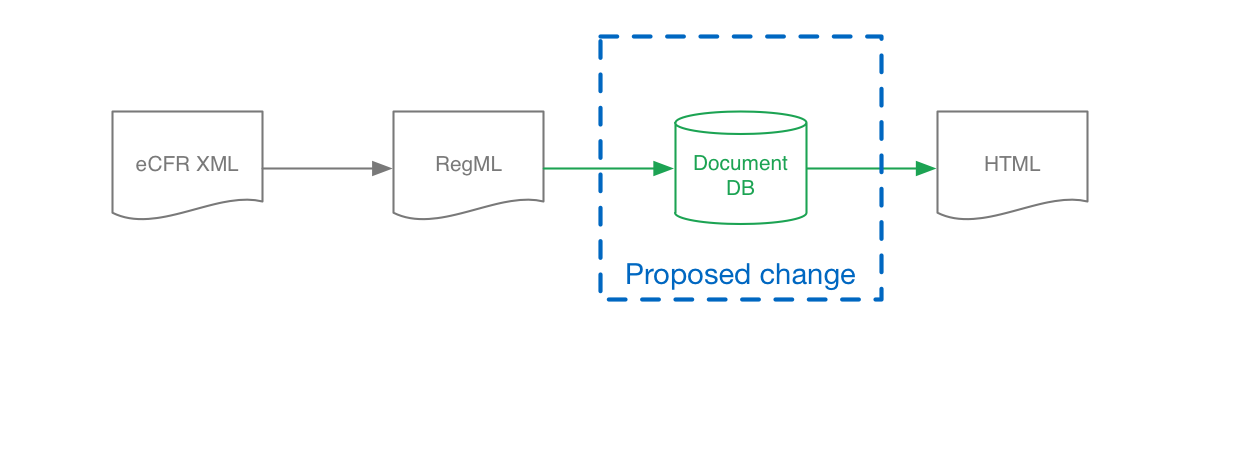
URL scheme
The old eRegs API contained a complicated URL scheme which required a great deal of complicated server-side processing in order to render the appropriate content. The new API simplifies the URL scheme using the principle that there are three pieces of data that uniquely identify a node within the regulatory structure: the document number, the effective date, and the node label. Althought not every node in the tree has a label, every node either has a label or is uniquely associated with a labeled node (in principle, every node could have a label, if it is so desired), and any node that can be navigated to has a label.
The document number identifies the actual document, as issued by the Federal Register, in which the content originates. For example, the initial document that originates Regulation C has the document number 2011-31712. A document contains at least one, but possibly more effective dates, which indicate on which date the regulatory text becomes effective. An example of this is a document that amends Regulation C, 2015-26607, which contains three effective dates (1/1/2017, 1/1/2018, and 1/1/2019). Obviously, multiple regulations may become effective on the same date.
The label of a node uniquely identifies the node within that specific regulation tree. With a few exceptions, the label consists of the part number, either the section number or the appendix letter, and the paragraph marker(s), separated by dashes. For example, Section 1 in Regulation C will have the label 1003-1, the first paragraph in that section has label 1003-1-a and so on. Nodes for interpretations have the form of the node to which they are appended, followed by the word Interp, and then followed by paragraph markers indicating the internal structure of the interpretation paragraph or section. So, for example, the interpretation of paragraph (a)(1) of section 3 will have the label 1003-3-a-1-Interp, and its first paragraph would have the label 1003-3-a-1-Interp-1, and so on.
Together, the document number, the effective date, and the label, separated by colons, are combined into a uniquely identifying node_id. Thus, paragraph (a) of section 1 of Regulation C from the document 2011-31712 effective on 2011-12-30 will have the node_id of 2011-31712:2011-12-30:1003-1-a. Accoringly, that node (or any other node with a label) can be accessed via the url localhost:8000/regulation/2011-31712/2011-12-30/1003-1-a.
Model logic
The entire storage logic of the new eRegs is rooted in a single model, RegNode. That model defines the basic properties of a node (label, text, tag, node_id). It also defines a version property, which is the document number and effective date concatenated together with a colon, e.g. 2011-31712:2011-12-30. There is also an attribs property which is a JSONField (present only in MySQL 5.7+ and PostgreSQL 9.3+). The attribs field contains all the data that would be present as an attribute in the RegML, e.g. <paragraph marker=(a)> would generate a RegNode whose attribs dictionary would contain a marker key whose value is (a). The RegNode inherits some generic node functions for fetching descendants and ancestors of an element in a nested set (GenericNodeMixin) and provides some additional functionality for testing the type of internal list that the node contains, if any, and which of its children have content, if any.
Subsequent node types are derived from RegNode as proxy models, which means that they do not have their own table; they are simply extensions of the RegNode that provide additional functionality. So, for example, the Paragraph model contains additional functionality for displaying the paragraphs, and so on. There is a one-to-one correspondence between the tag of a node (as obtained from the RegML), which allows automatic inference of node class when retrieving descendants and ancestors.
The only special node that is derived from RegNode is the DiffNode, which does have its own table. The difference between RegNode and DiffNode is that the DiffNode contains two version fields, left_version and right_version, which carry the same semantics as the version field of RegNode. Thus, every DiffNode in the table encodes the difference between the left and right versions of the regulation. As noted in the installation guide, diffs are not symmetric; thus a DiffNode with left version = X and right_version = Y is not necessarily identical to one with left_version = Y and right_version = X. Additionally, all node models which can encode version-differing content have accessory functions for retrieving the left and right versions of the content, as well as for rendering it.
View logic
The view logic in eRegs 2.0 is also drastically simplified relative to the old version of eRegs. The basic structure of a view is that it's identified by its functionality prepended to the aforementioned URL scheme, so that e.g. a node within a regulation has the relative URL regulation/2011-31712/2011-12-30/1003-1-a. Most of the other views are intended to render partials, and thus the URL is prepended with e.g. partial/sxs/ or partial/definition/. Views that render partials return the appropriate HTML directly to the caller, which can then be appended in the correct place on the front-end.
Template logic
The major templating work happens in the regnode.html file. The basic logic of that file is to render the regulation tree, starting at the specified root node, in a recursive fashion. Thus, depending on the type of node, regnode.html renders the opening HTML tag, recurses into the node to render its insides, and then renders the closing HTML tag on the way back up. There are some templates that render content independent of this structure (for example the sidebar, analysis, and table of contents are rendered separately). This simplifies the process of the old eRegs, in which the various JSON layers were assembled into the final rendered HTML; instead, there is a single point of entry for most rendering and substantially fewer places where an exception could happen.